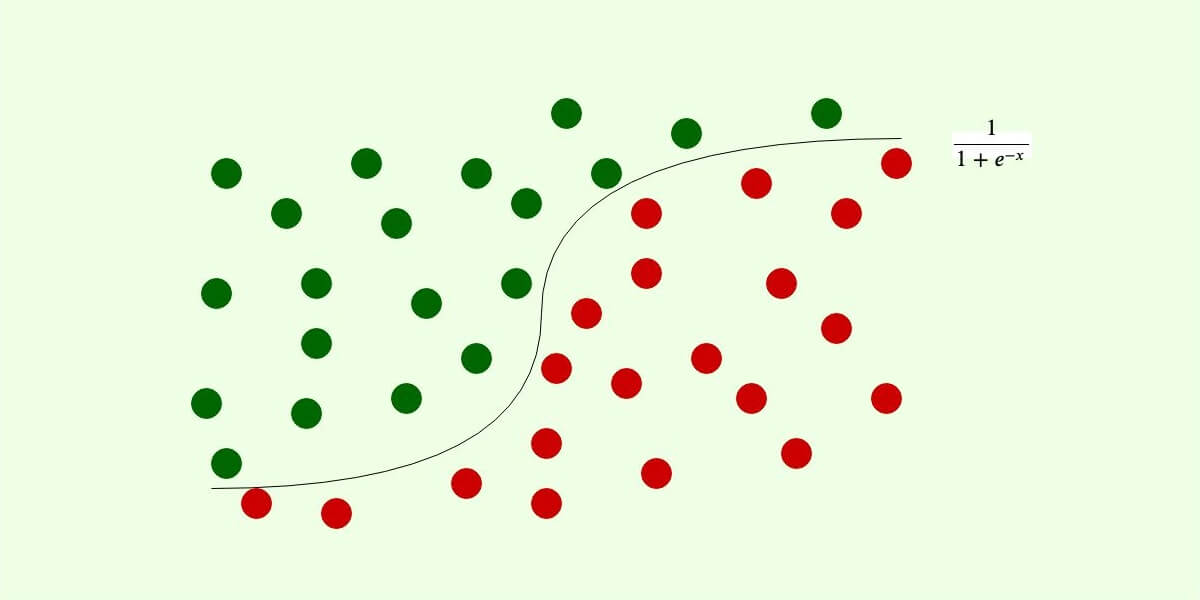
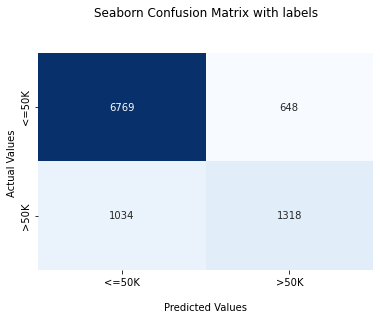
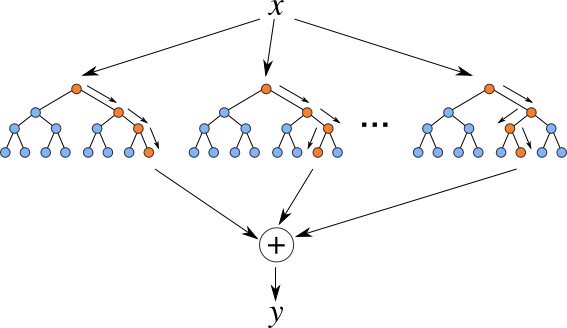
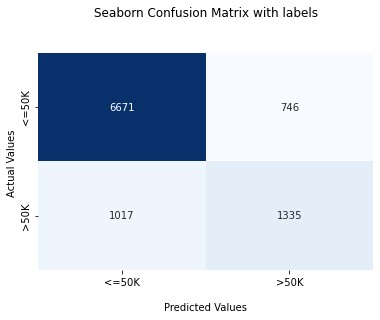
Exploratory Data Analysis
Exploratory data analysis is important for any business since it allows data scientists to analyze the data before coming to any assumption. It ensures that the results produced are valid and applicable to business outcomes and goals. An EDA is a thorough examination meant to uncover the underlying structure of a data set and is important for a company because it exposes trends, patterns, and relationships that are not readily apparent.

Gender Distribution
Distribution of gender in >50K and <50K

Gender Pay Gap
Is there gender bias in pay?

Race
Does Race have any impact on salary earned?

Age Distribution
Is age one of the factor in earning salary?

Higher Education
Does higher education translates into higher income?

Correlation Heat Map
Any correlation between features and salary?